از بین بردن پیچیدگی استقرار LLM های بومی ابری با LangChain و Intel Developer Cloud

نویسنده: آرون گوپتا و ازکیل لانزا
تصور کنید که می توانید برای هر کارمندی یک دستیار شخصی فراهم کنید. بهرهوری در سراسر سازمان شما افزایش مییابد زیرا کارمندان میتوانند ببینند که هوش مصنوعی چگونه میتواند به آنها کمک کند و برای تمرکز بر تفکر استراتژیک احساس قدرت کنند. این سناریوی رویایی با فناوری هوش مصنوعی قدرتمند، مانند رباتهای گفتگوی دپارتمان که نتایج سریع و باکیفیت ارائه میکنند، ممکن شده است.
با این حال، شرکت ها اغلب نیاز به ادغام چندین مدل زبان بزرگ (LLM) با هم دارند تا از موارد استفاده متنوع پشتیبانی کنند. از آنجا که هر مدل ممکن است نیازهای محاسباتی و ذخیره سازی متفاوتی داشته باشد یا دانش خاصی برای استفاده توسط بخش های داخلی به روش های منحصر به فرد داشته باشد، پیچیدگی می تواند خیلی سریع افزایش یابد.
مجموعه مناسب ابزارها می تواند پیچیدگی را از روند استقرار حذف کند. در اینجا ما یک معماری مرجع برای ساخت و استقرار چندین LLM در یک UI واحد با Kubernetes و LangChain را بررسی خواهیم کرد. همچنین میتوانید توضیح جامع هر مرحله را در مخزن مربوطه GitHub بیابید، که به عنوان یک منبع آموزشی با فایلهای دستور پخت طراحی شده است و میتوانید آن را دانلود کرده و ظروف خود را بسازید.
ما مراحل کامل این رویکرد را در ارائه KubeCon + CloudNativeCon Europe 2024 نشان میدهیم که میتوانید آن را به طور کامل در اینجا تماشا کنید.
مرحله 1: مدل خود را تعریف کنید
Hugging Face دانلود مدل ها را آسان می کند، بنابراین می توانید بلافاصله استدلال محلی را شروع کنید، اما چگونه می دانید کدام LLM را انتخاب کنید؟ علاوه بر تصمیم گیری در مورد استقرار مدل به صورت محلی یا خارجی (که در مرحله بعدی به آنها خواهیم پرداخت، سه نکته مهم وجود دارد که باید در هنگام ارزیابی گزینه های خود در نظر داشته باشید).
· کارایی: قبل از دانلود مدل، میتوانید با مقایسه آن با سایر مدلهای موجود در Hugging Face Leaderboard، یک سیستم رتبهبندی عمومی برای تابلوهای LLM باز، ببینید که چگونه با استانداردهای صنعتی مقایسه میشود.
· پشتیبانی جامعه: شما نمی خواهید مدلی را انتخاب کنید که هیچ کس استفاده نمی کند یا نگه می دارد. به دنبال مدلی باشید که دارای پذیرش گسترده جامعه، پایگاه مشارکتکنندگان فعال و مستندات قوی با منابع مفیدی مانند آموزشها باشد. اینها همه نشانه های یک جامعه پر رونق است که می تواند کمک مورد نیاز شما را در آینده ارائه دهد.
· ملاحظات اخلاقی: گاهی اوقات مدل ها نتایج مغرضانه ای را در مورد ویژگی هایی مانند نژاد یا جنسیت ایجاد می کنند. انتخاب مدلی که بر روی دادههای متنوع آموزش میدهد و در مورد فرآیندهای آن شفاف است، میتواند به شما در کاهش تعصب و اطمینان از منصفانه بودن نتایج کمک کند.
بسته به مورد استفاده خود، ممکن است بخواهید مدل خود را نیز بهینه کنید. به عنوان مثال، ابزاری مانند Intel® Extension for Transformers می تواند به شما کمک کند RAM مورد نیاز برای ذخیره مدل چت LLaMa2 با پارامتر ۷ میلیاردی را از ۲۶ گیگابایت به ۷ گیگابایت کاهش دهید.
مرحله 2: مدل مصرف را انتخاب کنید
هنگامی که یک مدل را انتخاب کردید، باید به این فکر کنید که آن را در کجا مصرف خواهید کرد. مدلهای محلی را میتوان در سرورهای داخلی یا حتی لپتاپها در صورت بهینهسازی ذخیره کرد، در حالی که مدلهای خارجی به شما اجازه میدهند از LLMهایی استفاده کنید که توسط شخص ثالث میزبانی میشوند. عواملی مانند هزینه، ظرفیت ذخیره سازی و نحوه برنامه ریزی شما برای مدیریت داده های حساس به تعیین اینکه کدام مدل مصرف برای شما مناسب است کمک می کند.
برای مثال، اگر مدل شما توسط بخشهای مالی یا حقوقی استفاده میشود، که اغلب مشمول مقررات حفظ حریم خصوصی دادهها هستند، ممکن است بخواهید از یک مدل در محل استفاده کنید تا بتوانید بدون ارسال دادههای حساس به خارج از سازمان خود، استنتاج کنید. فرمهای درون محل به شما کنترل بیشتری برای انتخاب نحوه و زمان استفاده از آنها میدهند، و تیم شما را قادر میسازد تا از فرمها بهصورت آفلاین استفاده کند و آنها را برای کسبوکارتان سفارشی کند، که به آن تنظیم دقیق نیز میگویند. بهعلاوه، مدلهای داخلی احتمالاً از کارایی هزینه بهرهمند میشوند، زیرا برخی از مدلهای فراساحلی ممکن است از شما بخواهند برای هر توکن خروجی و ورودی هزینه کنید. هنگامی که از یک فرم مبتنی بر هزینه خارجی استفاده می کنید، برای ارسال درخواست و دریافت پاسخ هزینه پرداخت می کنید. شما باید اطمینان حاصل کنید که درخواست های شما به خوبی طراحی شده و به دقت بیان شده است تا پاسخ صحیح را بدست آورید. در غیر این صورت، چندین ادعا ارسال می کنید و هزینه های خود را افزایش می دهید.
با این حال، مدل های خارجی مزایایی دارند که به توان محاسباتی و ذخیره سازی بسیار کمتری نیاز دارند. فرض کنید شما یک مدل LLaMa با پارامتر ۷ میلیارد دارید که به ۲۶ گیگابایت رم نیاز دارد. برای استنتاج مدل به صورت محلی، به فضای ذخیره سازی کافی روی سرور خود و همچنین قدرت محاسباتی لازم توسط CPU ها و GPU های محلی برای پشتیبانی از استنتاج مدل و برنامه خود نیاز دارید. با این حال، در مدل مصرف خارجی، شما فقط به قدرت محاسباتی کافی برای اجرای برنامه خود نیاز دارید – به سادگی یک تماس API برقرار کرده و شروع به استنباط کنید. علاوه بر این، از آنجایی که شخص ثالث منابع زیرساخت را مدیریت می کند، مدل های برون سپاری معمولاً راه اندازی آسان تر، استقرار سریع تر و مقیاس پذیری آسان تر هستند.
برای شروع تخمین هزینه یک مدل خارجی بر اساس ارائه دهنده و تعداد کدهای ورودی و خروجی مورد نیاز، می توانید از ماشین حساب قیمت استفاده کنید.
مرحله 3: فرم های خود را بسته بندی کنید
همانطور که LLM را که برای پشتیبانی از مهمترین موارد استفاده خود استفاده می کنید محدود می کنید، به روشی واحد برای مدیریت همه مدل های خود به کارآمدترین روش ممکن نیاز دارید. LangChain یک چارچوب متن باز است که ایجاد و مدیریت انواع مختلف برنامه های LLM را در یک رابط کاربری ساده می کند. شما می توانید هر یک از بیش از 80 نوع پشتیبانی شده از نرم افزار منبع باز LLM را متصل کنید، از جمله مدل های محلی و خارج از محل، مدل های بهینه و غیربهینه، و حتی تکنیک های پیشرفته مانند بازیابی تولید افزوده (RAG).
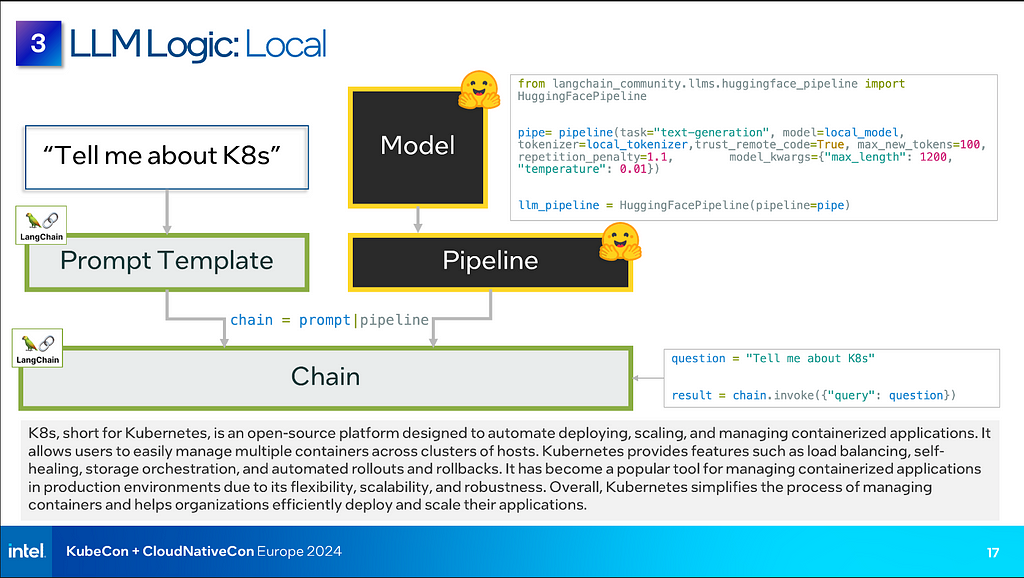
با این حال، همانطور که می بینید، برنامه LLM فقط یک مدل نیست. برنامه های کامل شامل یک مدل، پارامترها و نشانه هستند که Hugging Face در پیکربندی های متعددی به نام خطوط لوله ارائه می کند. علاوه بر این، LangChain یک الگوی سریع ارائه می دهد که زمینه بیشتری را برای نتایج بهتر به خط لوله ارائه می دهد. LangChain یک API به نام Chain، در میان چیزهای دیگر، ارائه میکند که الگوی ادعا و خط لوله را با هم ترکیب میکند، به طوری که تعامل با فرم به سادگی استفاده از “chain.invoc” برای ارسال سوال و ایجاد پاسخ میشود.
مرحله 4: مدل خود را در یک ظرف قرار دهید
از یک توسعهدهنده بپرسید که چگونه ترجیح میدهند نرمافزار LLM خود را استقرار دهند، و بیشتر اوقات آنها Kubernetes را میگویند. Cloud Native به پلتفرم واقعی برای استقرار LLM تبدیل شده است زیرا برخی از مزایای کلیدی را ارائه می دهد.
· مقیاس پذیری و قابل حمل بودن: پس از پیکربندی یک مدل در یک خوشه روی دسکتاپ، میتوانید بهطور یکپارچه آن را در بین پلتفرمها – مانند Amazon EKS، Microsoft Azure، یا Intel® Developer Cloud – و محیطهای تولید، از داخل محل تا لبه و از کوچک تا بزرگ مقیاسبندی کنید. خوشه های گره
· مدیریت منابع: مدل های هوش مصنوعی حافظه و قدرت محاسباتی زیادی مصرف می کنند. Kubernetes به شما کنترل بیشتری میدهد تا منابع خود را در محدودیتهای CPU و حافظه، سهمیههای منابع و کلاسهای اولویت تنظیم کنید تا ابتدا برق را به مهمترین مدلها هدایت کنید.
· قابلیت مشاهده: بسیاری از پروژه های منبع باز از تله متری برای بهبود دید و ارائه دانش بیشتر در مورد مدل های هوش مصنوعی استفاده می کنند.
درست مانند فرآیند پر کردن فرم در مرحله قبل، LangChain همچنین یک API ارائه می دهد تا به شما کمک کند فرم خود را به راحتی در یک ظرف قرار دهید. با اتصال ظرف خود به سرور فایل از طریق درخواست Persistent Volume (PVC) یا Persistent Volume (PV) شروع کنید. اکنون، هنگامی که کانتینر را اجرا می کنید، POST API فرم را از سرور فایل دانلود می کند و آن را در داخل ظرف قرار می دهد.
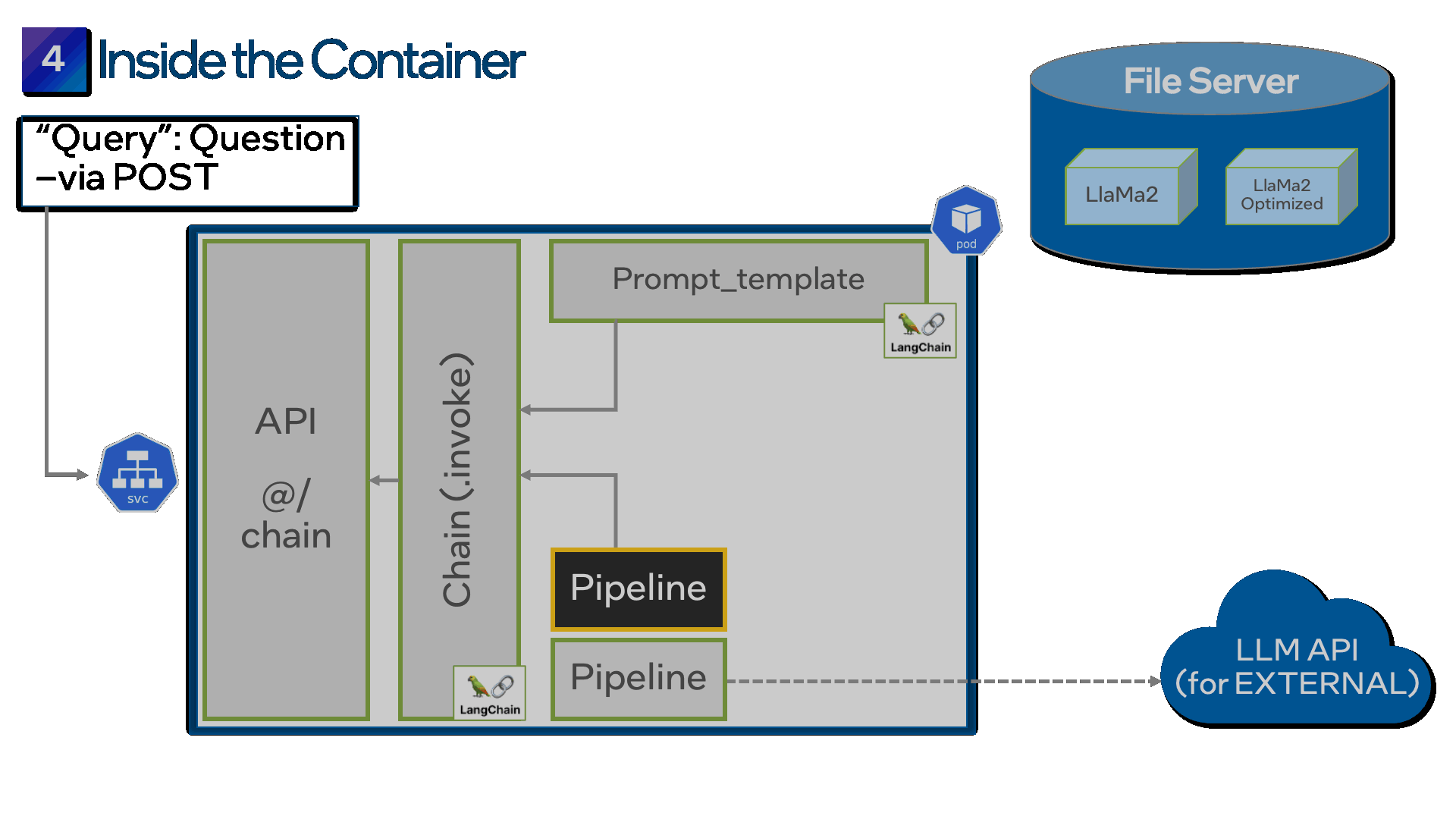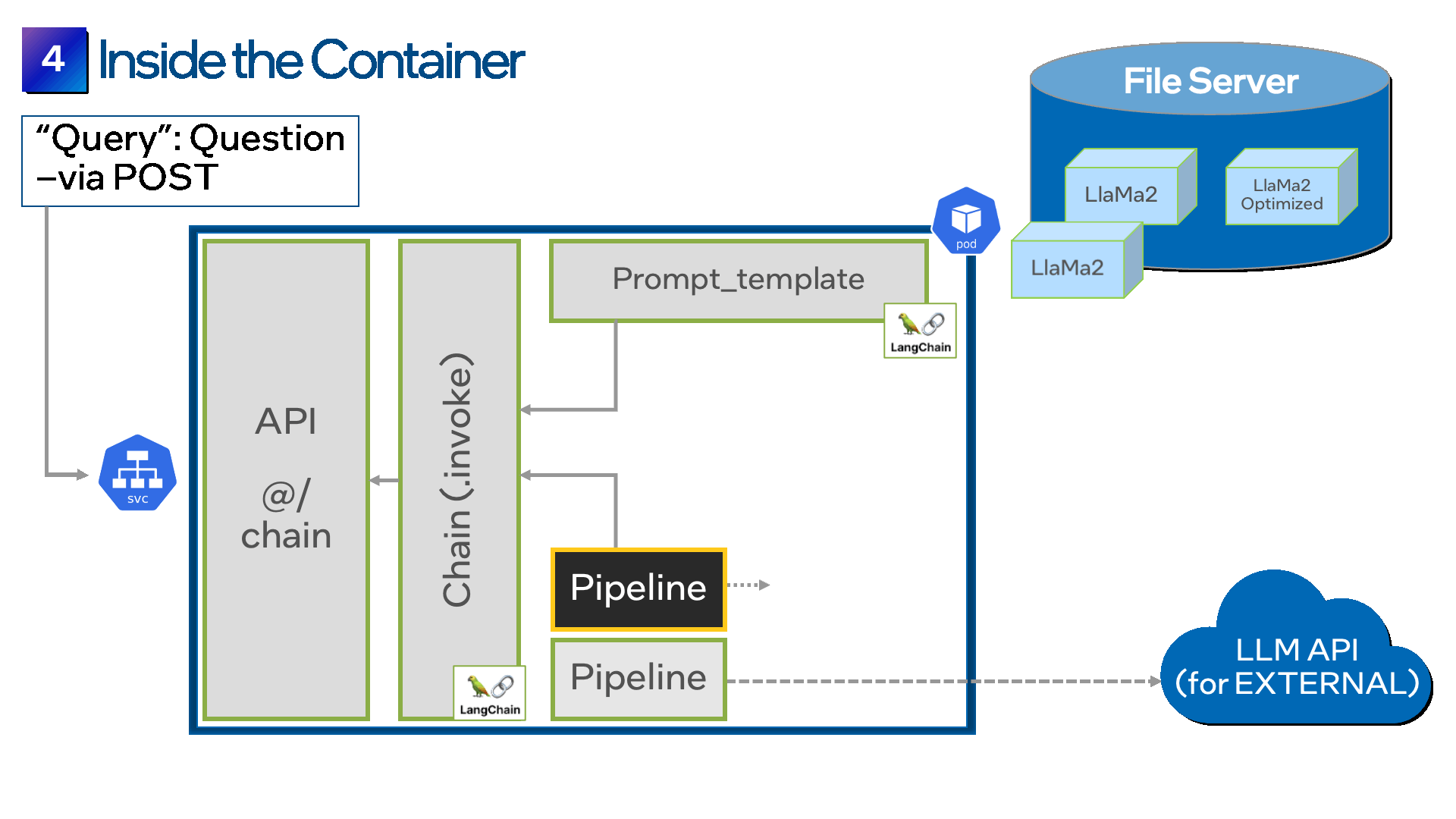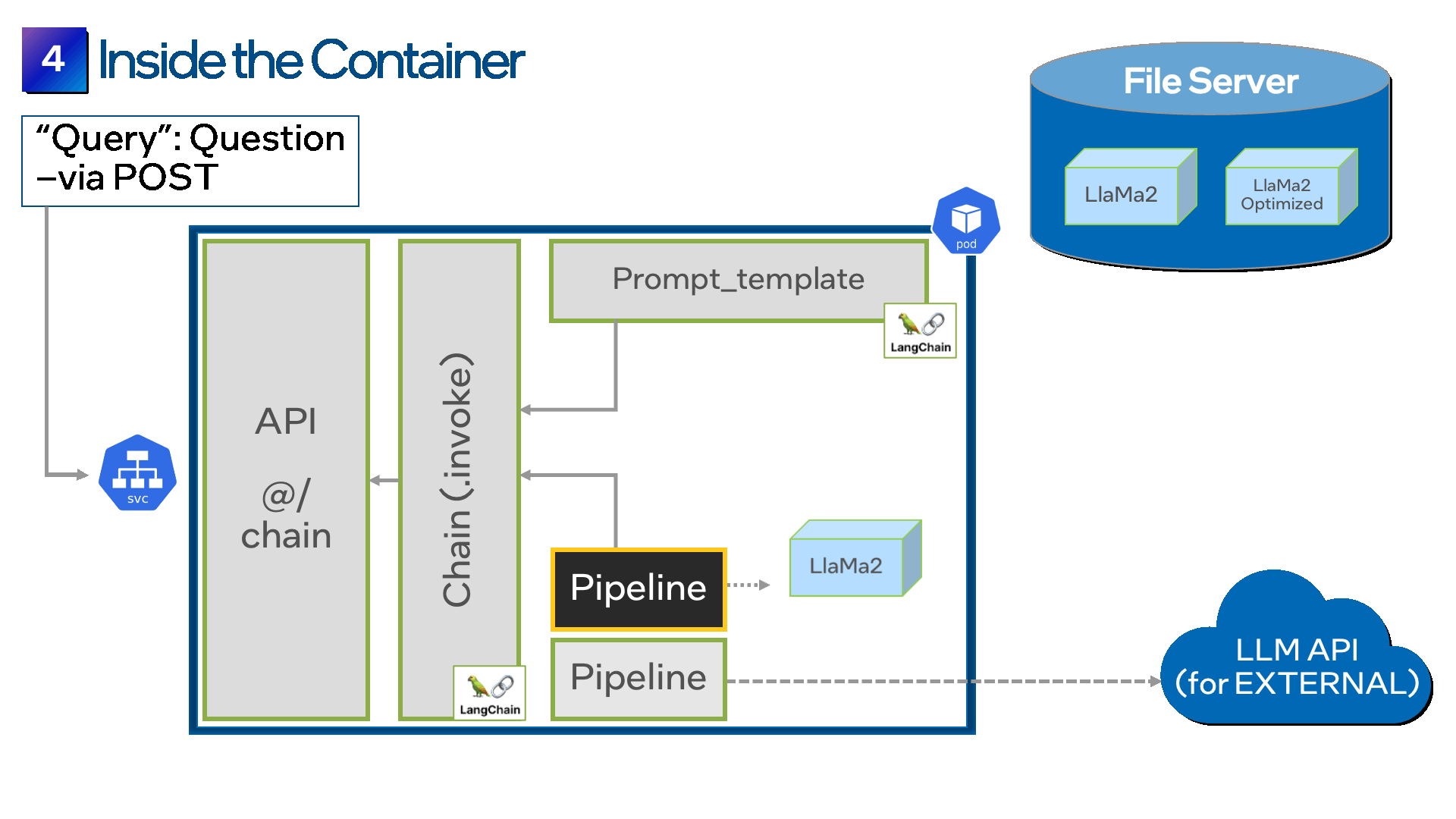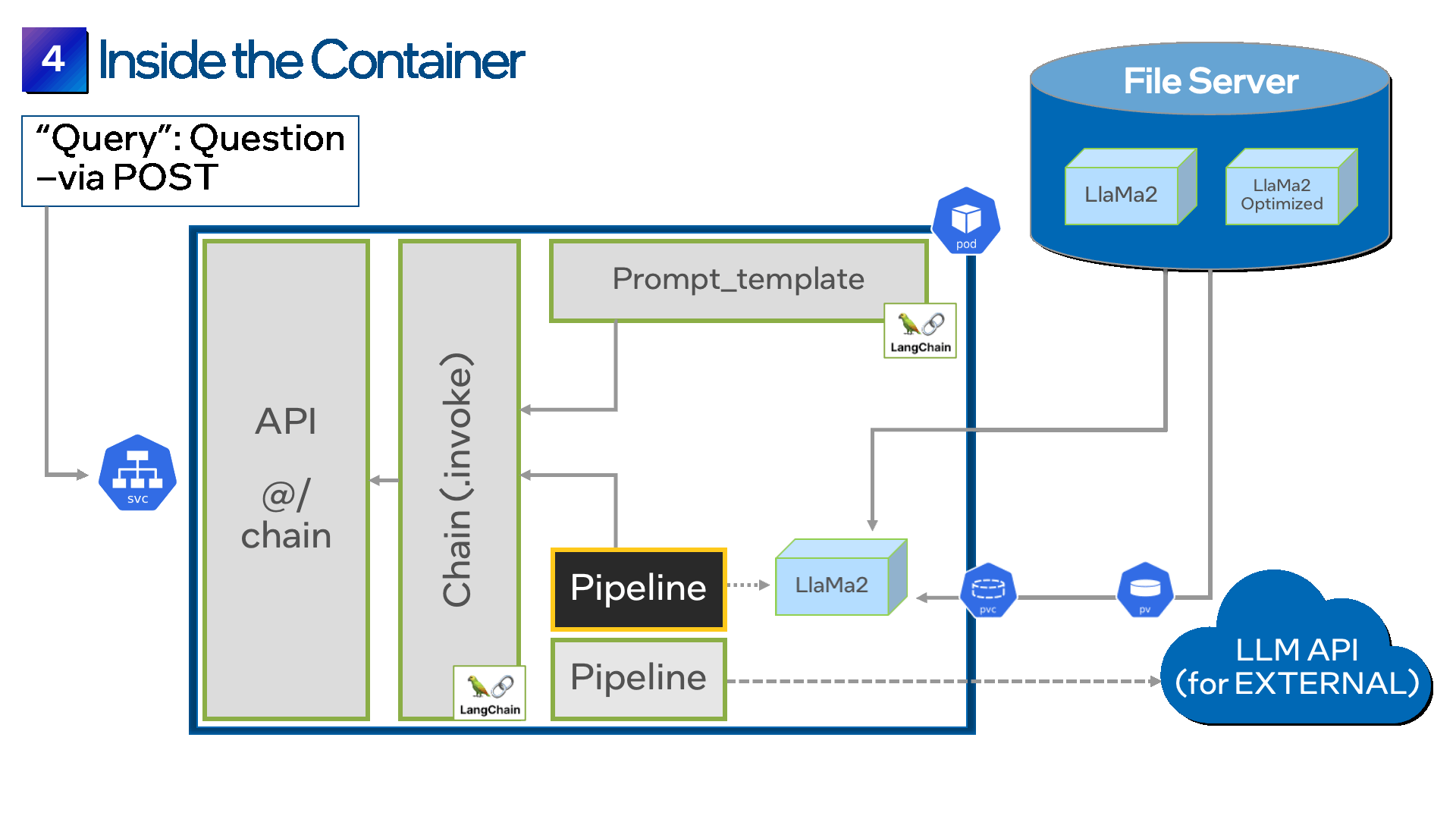
مرحله 5: چندین مدل را ادغام کنید
اکنون که مدل خود را کامپایل کرده اید و آن را کانتینری کرده اید، ممکن است بخواهید LLM های دیگری را که برای موارد استفاده جدید به خوبی تنظیم شده اند، اضافه کنید. برای انجام این کار، به یک عامل LLM نیاز دارید – یک لایه معماری که LLM های متمایز را متحد می کند تا بتوانند با چندین مدل به طور همزمان تعامل داشته باشند.
به عنوان مثال، اینترانت سازمان خود را در نظر بگیرید. این کارمندان در سراسر سازمان شما را به ابزارهایی که برای تکمیل کارشان، برقراری ارتباط بین واحدهای تجاری و دسترسی به اطلاعات مهم در مورد وضعیت شغلی خود، مانند برگه های حقوق، درخواست های PTO و فرم های مالیاتی نیاز دارند، متصل می کند. اتصال UI اینترانت به یک عامل LLM به کارمندان شما امکان می دهد به مدل های هوش مصنوعی بهینه شده برای هر واحد تجاری دسترسی داشته باشند.
علاوه بر ارائه ابزارهای مدیریتی برای ارائه مدلسازی و حاکمیت، یک عامل LLM ممکن است اطلاعات بیشتری را برای کمک به ادعاهای هوش مصنوعی و هدایت آنها به بهترین LLM برای حل مشکل در نظر بگیرد.
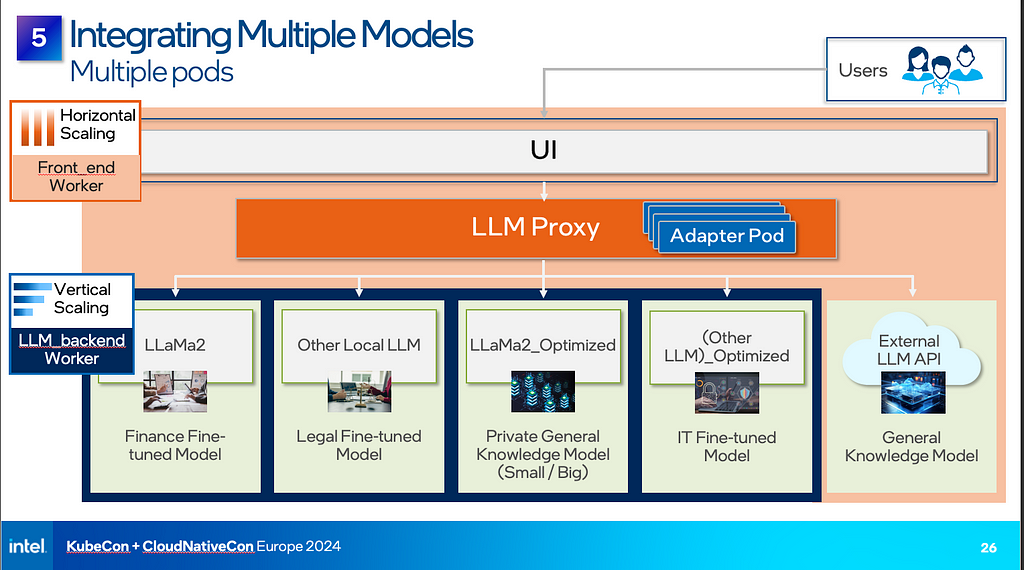
برای ایجاد این مورد در یک محیط Kubernetes، ابتدا یک کنترل کننده ورودی یا متعادل کننده بار، مانند NGINX، ایجاد کنید تا قسمت جلویی و پروکسی را در معرض دید قرار دهد تا مرورگر بتواند با آن ارتباط برقرار کند. همه چیز در زیر عامل، مانند فرمهای محلی یا APIهای فرم خارجی، نیازی به در معرض دید مرورگر ندارند و میتوانند به صورت داخلی بهعنوان غلاف در خوشه مستقر شوند. هنگامی که کانتینرهای خود را به یک رجیستری کانتینری مانند Docker Hub فشار دهید، زمانی که خوشه شما در حال اجرا است، کانتینرهای شما قابل دسترسی خواهند بود.
نسخه ی نمایشی: استقرار یک چت بات در Kubernetes در اینتل Developer Cloud
در این نسخه ی نمایشی سریع، ما به شما نشان خواهیم داد که چگونه یک ربات چت را استقرار دهید که می تواند با استفاده از LangChain و Intel Kubernetes Service (IKS) بین چندین مدل جابجا شود. IKS یک سرویس Intel® Developer Cloud است که به شما امکان میدهد برنامهها را به محض در دسترس بودن، بهجای اینکه منتظر باشید تا ارائهدهنده ابری سختافزار را تأیید کند، روی جدیدترین سختافزار Intel® آزمایش کنید. همچنین می توانید فایل های لازم را از مخزن GitHub دانلود کنید تا کانتینرهای خود را اجرا کرده و ادامه دهید. همانطور که خواهید دید، نتایج با استفاده از React در یک رابط کاربری ساده ماکتآپ ظاهر میشوند.
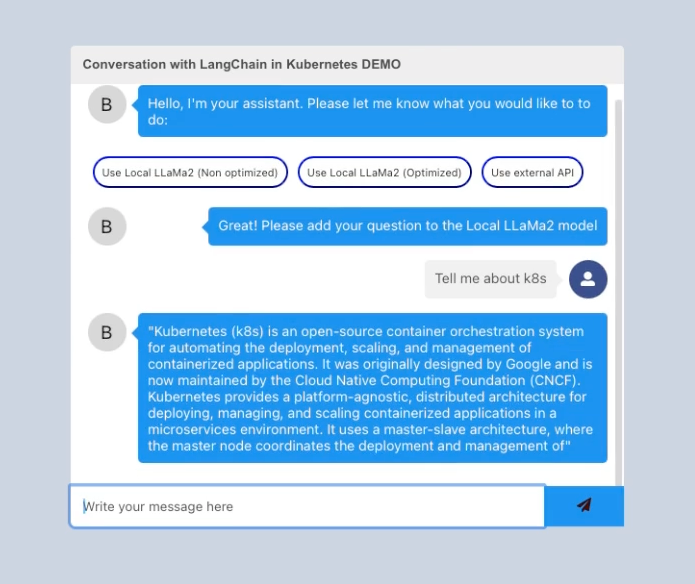
خودت آن را امتحان کن
مدلهای هوش مصنوعی میتوانند به بهبود بهرهوری کارکنان در سراسر سازمان شما کمک کنند، اما یک مدل به ندرت برای همه موارد استفاده مناسب است. LangChain استفاده از چندین دارنده مدرک LLM را در یک محیط آسان می کند و به کارمندان اجازه می دهد مدل مناسب را برای هر موقعیتی انتخاب کنند. برای شروع کار با LangChain و IKS، مخزن GitHub را کاوش کنید.
درباره نویسندگان
Ezequiel Lanza، مبشر هوش مصنوعی منبع باز، اینتل
Ezequiel Lanza یک مبشر متن باز در تیم Open Ecosystem در اینتل است که مشتاق کمک به مردم برای کشف دنیای هیجان انگیز هوش مصنوعی است. او همچنین یک ارائه کننده مکرر در کنفرانس های هوش مصنوعی و ایجاد کننده موارد استفاده، آموزش ها و راهنماها برای کمک به توسعه دهندگان برای استفاده از ابزارهای AI منبع باز است. او دارای مدرک کارشناسی ارشد در رشته علوم داده است. آن را در X در پیدا کنید @eze_lanza.
آرون گوپتا، معاون و مدیر کل، Open Ecosystem، Intel
آرون گوپتا که به رشد اکوسیستم باز در اینتل اختصاص دارد، یک استراتژیست، مدافع و متخصص است که دو دهه را صرف کمک به شرکت هایی مانند اپل و آمازون در پذیرش اصول منبع باز کرده است. او در حال حاضر رئیس بنیاد محاسبات بومی ابری است.
ما را دنبال کنید!
متوسط، پادکست، Open.intel، ایکس لینکدین
Easily Deploy MBA های متعدد در یک محیط Cloud Native در ابتدا در Intel Tech در Medium منتشر شد، جایی که افراد با برجسته کردن و پاسخ دادن به این داستان به گفتگو ادامه می دهند.



